Background
Objective
Modern processors include a vector ALU to perform SIMD operations which speed up or paralellize certain computations. SIMD execution in modern processors showcase some of the problems we have studied this term, like synchronization and branch prediction problems. The goal of this lab is for you to experiment with the use of the vector ALU in the RISCV-V extension and to gain a deeper understanding of problems that can be more efficiently solved using SIMD execution and some problems that see performance degrade through the use of SIMD instructions.
About Vector instructions in RISCV-V
You can refer to the RISCV-V specification for precise semantics of all operations that occur in the vector unit, however I will outline a number of key points for this assignment.
Reading in section 4.4, we divide a vector register into elements. We can define the width of a vector register (VLEN) as any value larger than the element width (ELEN) that is also a power of 2, to a maximum of , however there are some common architecture profiles that can set further limits on both ELEN and VLEN. VLEN and ELEN are both taken as properties to your system architecture in gem5.
To get you started with the vector extension in gem5, you can specify an architecture on your System() object like so:
from m5.objects import *
system = System()
system.arch = RiscvISA()
Masked Operations
Section 16.1 specifies the semantics for masked operations in RISCV-V. This allows us to efficiently handle operations that should only apply to certain elements in our vector register. In the assignment we will be playing with this.
You can look at this like the dataflow of each element in the vector register. If you have control flow within a vectorized operation, then you may need to perform some operations on only part of the vector register's elements. Below is an illustrative example:
# char* strcpy(char *dst, const char* src)
strcpy:
mv a2, a0 # Copy dst
li t0, -1 # Infinite AVL
loop:
vsetvli x0, t0, e8, m8, ta, ma # Max length vectors of bytes
vle8ff.v v8, (a1) # Get src bytes
csrr t1, vl # Get number of bytes fetched
vmseq.vi v1, v8, 0 # Flag zero bytes
vfirst.m a3, v1 # Zero found?
add a1, a1, t1 # Bump pointer
vmsif.m v0, v1 # Set mask up to and including zero byte.
vse8.v v8, (a2), v0.t # Write out bytes
add a2, a2, t1 # Bump pointer
bltz a3, loop # Zero byte not found, so loop
ret
Consider the call copying the string char* src = "hi", that is the byte vector [ 0x68, 0x69, 0x00 ] and we assume ELEN = 2^8 and VLEN = 4 * ELEN. This would lead to the following flowchart given the above implementation:
Keep this in mind and consider how a convolution works as shown in the gif below:
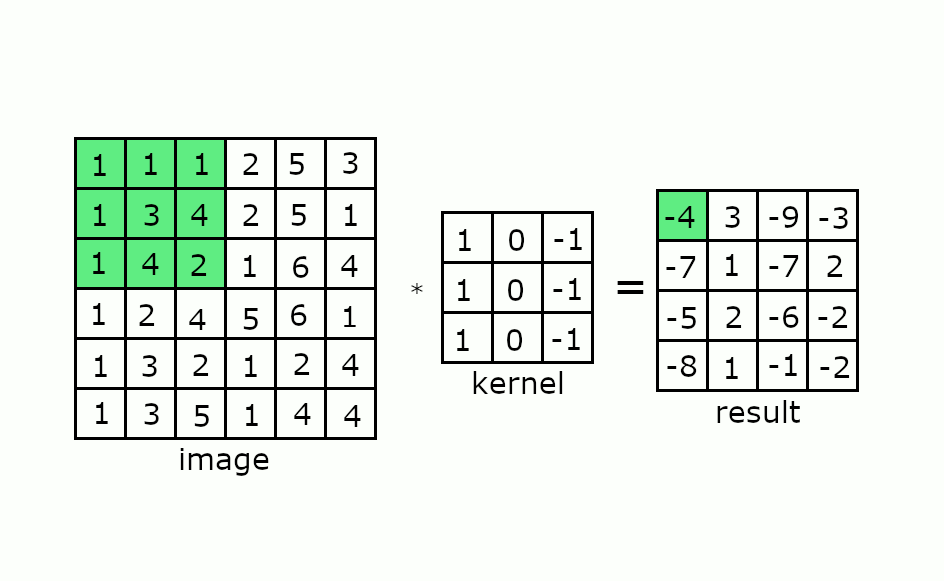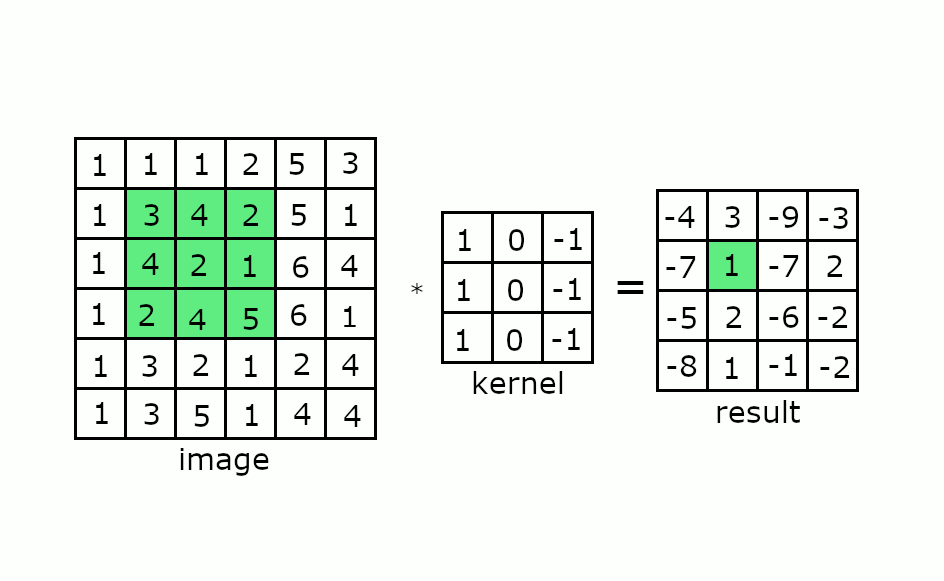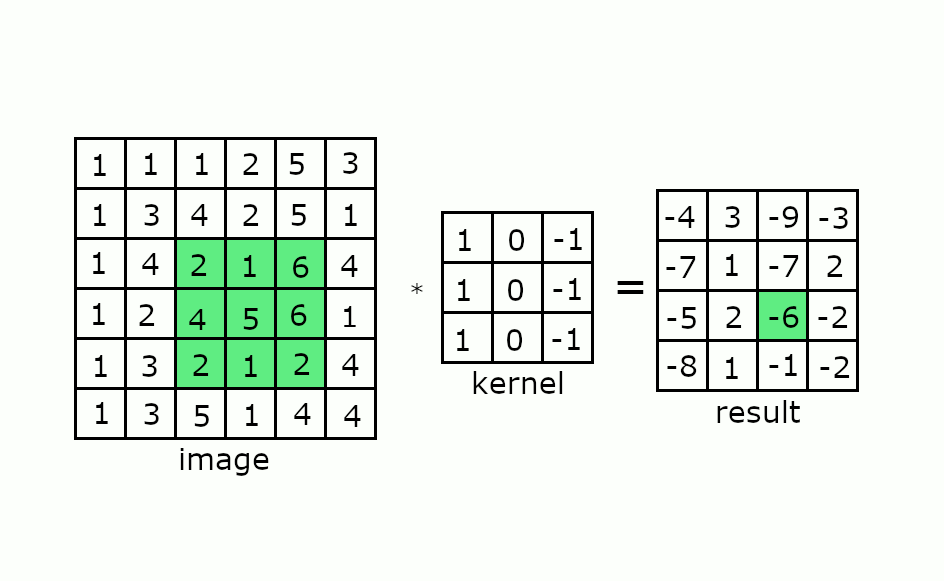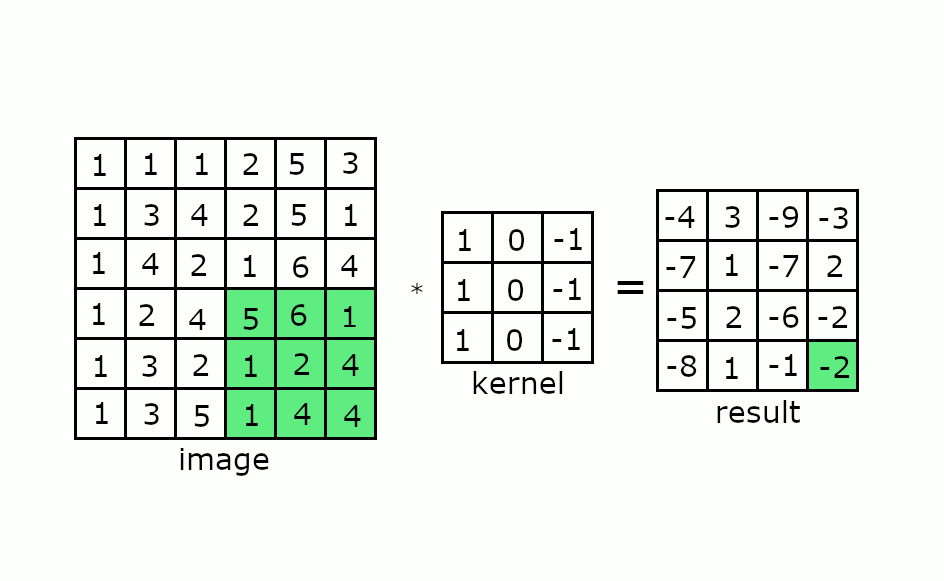
If you consider our four-element wide vector register, then we might need to perform masking on the convolutional kernel in order to obtain the correct resulting matrix. This masking of arithmetic operations can reduce the throughput of these operations if not architected correctly.
Convolution is common in image processing, particularly in convolutional neural networks (hence the name) such as the U-net. If you're at all curious, the convolution allows image processing neural networks to maintain data about the locality of image features in the low-dimensional latent-space that the network can then use to perform inference. Particularly, this is useful in image segmentation.
Recently the image processing gang is moving towards the use of vision transformers for image operations, but you can still perform a vision transformer step using a special case of the convolution where the stride is equal to the dimensions of the kernel.
More specifically, consider the convolution in the image above, but instead of moving by one 'pixel' each time, the green square would move by three 'pixels' (the width of the kernel) each time. If you're really curious about that, you might find this website, it provides an excellent introduction to deep learning and computer vision, however you will have to jump into the papers to get to vision transformers in any depth.
The Assignment
We expect you to work as a team of two, with the final partner assigned to you at the beginning of the course. The expectations are further detailed in our collaboration policy.
I'm literally begging at your feet for you to talk to your partner. Just do it, for my sake and so that Dr. Amaral does not need to burden himself with extra emails. I'm begging, on my knees. Please.
Please.
🙏
In this assignment, you will analyze how the use of a vector unit can affect the performance of various benchmarks. To do this, you will analyze the performance of several synthetic benchmarks as well as a benchmark from the SPEC suite with and without a vector unit.
Write scripts. Go see the scripts tutorial